The Data Science Of Good Writing
Stylometry is the application of the study of linguistic style to written documents - besides literary or qualitative analysis, modern stylometry leverages the power of natural language processing (NLP) and statistics. What if this was combined with machine learning (ML) techniques to discern any commonalities between "good" and "bad" literature? i.e. determine the "written habits" of good writers?
NLP, statistical stylometry, and ML are all complex topics, hardly coverable in a short article. Therefore, many details have been left out for the reader to investigate further. Instead, the aim here is to provide a brief overview along with an example of the process of doing "data science", that being a very generic term used to describe a wide variety of approaches and theories.
The specific framework described in this article is statistical learning, along with a basic explanation of how the ML approach of cluster analysis could be used as a starting point to investigate the question of "what makes up 'good' writing?" From this basis, a system could then be designed to aid in the process of reducing the "slush pile" of publishing houses in an automated fashion.
The major phases of any data science work are
- A) data collection and cleaning it up (aka data munging)
- B) analysis of the data
- C) building and validating models of the data
- D) visualization of the results
Explaining how to create visualizations is an entire set of articles, so only the first 3 steps are discussed below.
Data collection and munging are tedious steps, but necessary - the goal is to 1) get the raw data into a basic and uniform format (e.g. plain text files) and 2) to ensure consistency in the data (e.g. no extraneous text like appendices). Exactly what sort of munging is performed depends on the type of raw data and how problematic it is. Technically, this was straightforward work, but not very interesting as cleaning up text files is not complicated. This phase is typically more than 50% of the entire amount of work in a data science project.
"50 Shades of Grey" and "War And Peace" were the first two books that came to mind. Others used were "Pride and Prejudice", "The DaVinci Code", "A Christmas Carol", and "The War Of The Worlds" - books with a known quality that subjectively seemed to define a range.
Then some random books from Project Gutenburg were used to fill out a sufficiently large enough data set: "The Sexy Lady", "Dave Dawson With The Pacific Fleet", "The Sexy Lady", "The Eye of Alloria" and "1st To Die". The result of all the data processing was ASCII files, with all the sentences on one line (some NLP tools treat line breaks as periods, for example).
With this standardized data, a few NLP tools (based on Python's Natural Language Toolkit) were then used to calculate different statistics. Some are obvious ones to use, such as the percentage of different parts of speech (adverbs, nouns, adjectives) or the size of the vocabulary.
But others are specific to linguistics - 'readability' is a notable one. There are actually several different formulas for "readability" that use different measures, such as the number of polysyllable words or the average sentence length. These formulas reduce the measures into a single number that relate to the (US based) grade level needed to comprehend the text.
Some more examples of the statistical measures calculated were:
- filler_ratio (words that don't add much meaning: e.g. very, much, just, actually)
- long_sentences_ratio
- standard_deviation_of_words_per_sentence
- words_per_sentence
- stopword_ratio (stopwords are words such as 'it' or 'the')
- noun_cluster_ratio (3 or more consecutive nouns)
- passive_voice_ratio (% of sentences using the passive voice)
- syllables_per_word
How could these statistics be used in finding commonalities between "good" literature and also distinguish "bad" writing? This is essentially a classification problem; one ML technique for solving this is k-means clustering. K-means clustering works by, for each data point, determining the "distance" of it to an arbitrarily selected central point that denotes a cluster. Through an iterative process, the set of optimum central points is determined such that the total "distance" from each to each of the data points within that cluster is minimized. "Distance" is in quotes because each data point is actually a vector composed of the statistics.
An interactive tutorial with a visual explanation can be found at OnMyPhD
Analogous to this process, and perhaps easier to comprehend, is the concept of linear regression and finding the mean squared error. Khan Academy's videos on linear regression provide a visual explanation of the process of minimizing the "distance" of a collection of points to a line that represents the "ideal". K-means clustering is merely an enhancement of the basic idea - and can be extended to not just 2, but 3 or more dimensions.
Dealing with 33 dimensional vectors (33 statistics) would require notable CPU time. To reduce the work, another data science concept was used - feature selection. This consists of using a subset of a data point's features (i.e. the statistics) which are more likely to be important. For example, word count is not useful in determining quality, otherwise Stephen King would have won the Nobel Prize already.
WEKA was then used to analyze the statistics in an exploratory way to find a possible starting point. One of WEKA's functions allows you to graph each feature against the others. These graphs let you visually determine if there might be some interesting correlations - e.g. all features of one class of books are clearly grouped together versus the other classes.
As an example, Figure 1 reveals that the graph of long_sentences_ratio versus adjective_ratio clearly showed a differentiation - the books in the "good" category were closer together and separate from the "bad" books. "Good" and "bad" are subjective measures in this case, but obviously a graph that results in any work of Jane Austen's being grouped with or near to E.L. James would be regarded as not useful. Long sentences versus adjectives makes intuitive sense - i.e. better authors tend to use longer sentences and more adjectives (less repetitive and simplistic writing), in general - Hemingway might be an outlier in this regard. There are several statistical techniques for handling outliers to reduce or compensate for their effect on the overall conclusions.
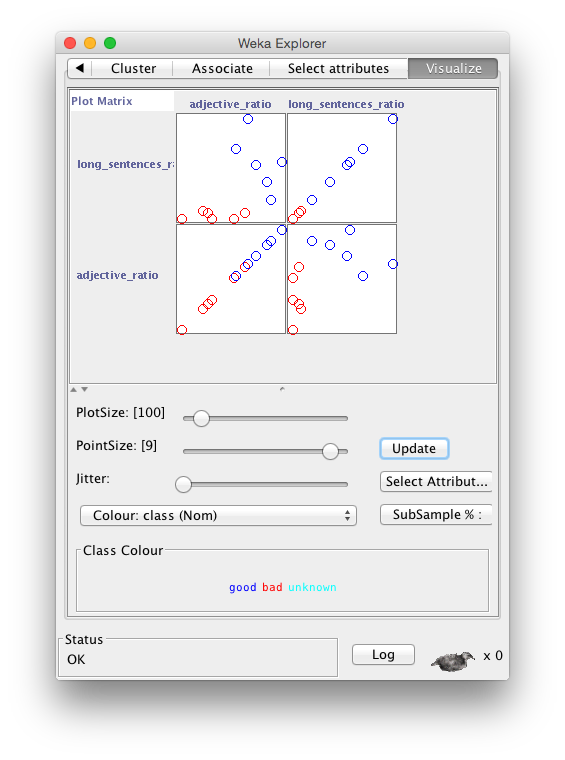
Once some possibly useful features were selected (i.e. a model by which the open question could be solved was built), WEKA's ability to run different types of clustering algorithms was used to validate the utility of this particular model. Running a K-means clustering algorithm on the data (using long_sentences_ratio and adjective_ratio) resulted in the books being 100% classified (or grouped) in an expected manner. K-means is only one of many possible algorithms that could be used and models based on other features using another algorithm might turn up interesting insights and results.
WEKA can be trained against known training data (supervised learning), or it can figure out how to create clusters itself (unsupervised learning) - but the results are never guaranteed. So there is typically a lot of iterations in building and validating models; below is the result of one run.
Cluster centroids:
Cluster#
Attribute Full Data 0 1
(12) (6) (6)
=======================================================
adjective_ratio 0.056 0.0511 0.061
long_sentences_ratio 0.0368 0.0052 0.0685
Clustered Instances
0 6 ( 50%)
1 6 ( 50%)
Class attribute: class
Classes to Clusters:
0 1 <-- assigned to cluster
0 6 | good
6 0 | bad
0 0 | unknown
Cluster 0 <-- bad
Cluster 1 <-- good
Incorrectly clustered instances : 0.0 0%
This is only a starting point - far more investigation will be needed to determine exactly what features are useful and how well other clustering algorithms may work. But overall, it seems safe to conclude that statistical analysis and clustering algorithms could form the foundation for a machine learning system that can distinguish what are the components of "quality" for works of literature.